Word frequency in Japanese documents.
This has been run in the following environment: Windows 7, mysql 5.1, ruby 1.9.1 (dbi 0.4.3, nokogiri 1.4.3.1)
To make life easier, some simplifications are made:
The dictionary (JMDict) used for the analysis is understandably rather incomplete with regard to go terminology. Example of words that are not in the dictionary: 手抜き (tenuki), 眼形 (eye shape), 利かし (kikashi). Examples of words that are in the dictionary: 攻め合い (semeai), 先手 (sente), 定石 (joseki).
We will manually add some go terminology to the dictionary database we create from JMDict.
Downloaded pages are saved with a path corresponding to their type and url. For example, the overview page for Meijin commentaries at "http://www.asahi.com/igo/meijin/PNDkansen_ichiran.html" is saved as "downloads/commentary/www.asahi.com/igo/meijin/PNDkansen_ichiran.html"
Pages to analyze: Game commentaries at http://www.asahi.com/igo
Algorithm:
pages_to_visit = ["http://www.asahi.com/igo/meijin/PNDkansen_ichiran.html"]
repeat until pages_to_visit empty:
pop url from pages_to_visit
download and save page
add links to pages_to_visit if
* the link starts with "http://www.asahi.com/igo/meijin"
* the link has not been visited before
later analyze all pages to see which include game commentaries and what part of the doc is the actual commentary
Script to download commentary pages: crawl_commentaries.rb
Pages to analyze: Articles on Japanese Wikipedia having category 囲碁 or one of its subcategories (recursively)
Algorithm:
pages_to_visit = ["http://ja.wikipedia.org/wiki/Category:%E5%9B%B2%E7%A2%81"]
repeat until pages_to_visit empty:
pop url from pages_to_visit
download and save page
add links to pages_to_visit if
* the current page is a 'Category page'
* the link is within the main section of the page (the page-specific part)
* the link has not been visited before
later analyze all pages to exclude category pages and extract the main section of the page
Script to download wikipedia pages: crawl_wikipedia.rb
Pages to analyze: News articles at http://www.nihonkiin.or.jp/news
Algorithm:
pages_to_visit = []
download "http://www.nihonkiin.or.jp/news/index.html"
add links to pages_to_visit if the link is in the list of news articles
n = 2
repeat until page not found error:
download "http://www.nihonkiin.or.jp/news/index_[n].html"
add links to pages_to_visit if the link is in the list of news articles
n = n + 1
repeat until pages_to_visit empty:
pop url from pages_to_visit
download and save page
later analyze all pages to extract the actual news text
Scripts to download news pages: crawl_news_1.rb and crawl_news_2.rb
Script to extract text from downloaded commentary pages: extract_commentary.rb
Script to extract text from downloaded wikipedia pages: extract_wikipedia.rb
Script to extract text from downloaded news pages: extract_news.rb
Data from the JMDict project is the main source for our dictionary database.
We will look for words and names and so the following dictionary files are needed:
dict.xmlnames.xmlBelow is a subset of the conceptual model of JMDict. Only parts that are relevant to this exercise are included. The terminology used is the one in the xml file.
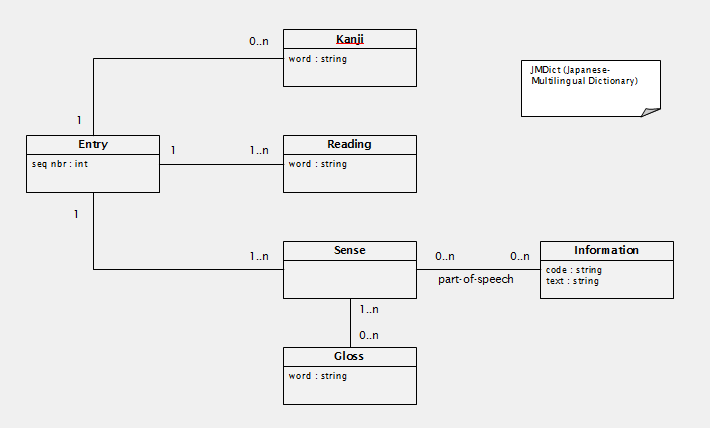
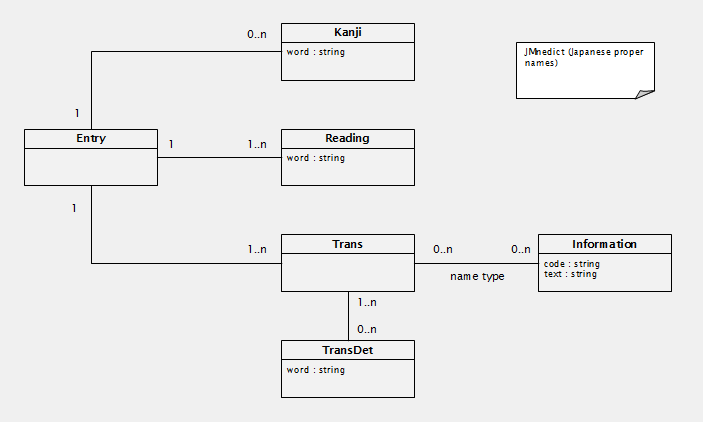
Below is a subset of the conceptual model of JMnedict. Only parts that are relevant to this exercise are included. The terminology used is the one in the xml file.
Integrated, with the added concepts lookup item and my entry. The schema terminology is changed to something more intuitive.
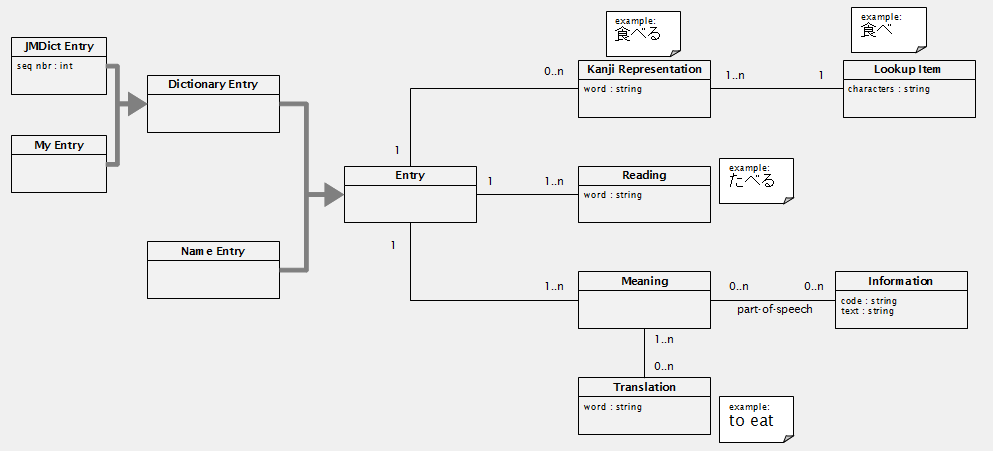
Relational schema:
entry (id*)
dictionary_entry (id* [fk to entry])
jmdict_entry (id* [fk to dictionary_entry], seq_nbr)
my_entry (id* [fk to dictionary_entry])
name_entry (id* [fk to entry])
lookup_item (id*, characters)
kanji_representation (id*, entry_id [fk to entry], word, lookup_item_id [fk to lookup_item])
reading (id*, entry_id [fk to entry], word)
meaning (id*, entry_id [fk to entry])
translation (id*, word)
meaning_translation (meaning_id [fk to meaning], translation_id [fk to translation])
information (code*, description)
part_of_speech (meaning_id [fk to meaning], information_code [fk to information])
Script to create database: create_database.sql
Script to create tables: create_tables.sql
Script to create database indexes useful during the upload of data: create_indexes_1.sql
Script to populate database with dictionary entries (169'037 as of 2013-05-09): upload_dict.rb
Script to populate database with name entries (738'657 as of 2013-05-09): upload_names.rb
Script to add entries missing in JMDict: upload_my.rb
Script to create the remaining database indexes and constraints: create_indexes_2.sql
Script to count the number of occurances of words in a file: count.rb
Run with:
ruby count.rb extracted_commentary.jtxt
ruby count.rb extracted_wikipedia.jtxt
ruby count.rb extracted_news.jtxt
The program creates the following files on each run:
word_frequency_[commentary/wikipedia/news].html | |
word_frequency_[commentary/wikipedia/news]_common.html | Only includes words with a frequency greater than 1 in 10'000 |
word_frequency_[commentary/wikipedia/news]_long.html | Includes dictionary data in the report |
word_frequency_[commentary/wikipedia/news].xml | |
visited_pages_[commentary/wikipedia/news].html | A list of all analyzed pages |